Enhancing AI-Powered Chatbots with a Robust RAG Pipeline
Introduction
In the realm of AI-powered chatbots, the Retrieval-Augmented Generation (RAG) technique has emerged as a crucial approach in developing smarter and context-aware systems. By merging the capabilities of retrieval (finding relevant data) and generation (using a language model to create human-like text), a system can not only respond based on pre-trained information but also adapt to real-time queries by fetching fresh, pertinent data.
In this blog post, we will delve into the process of constructing a RAG pipeline from scratch. We will utilize a simple setup involving Flask for API management, FAISS for efficient embedding search, and models like Ollama or llama.cpp for generating responses.
Understanding a RAG Pipeline
A RAG pipeline is designed to enhance a chatbot's functionality by enabling it to retrieve relevant information from a knowledge base or document store (e.g., PDFs, JSON files) and generate dynamic, context-rich responses. Unlike conventional chatbots that rely on preset scripts, a RAG-powered chatbot adopts a more flexible and scalable approach, making it highly effective for a wide range of applications.
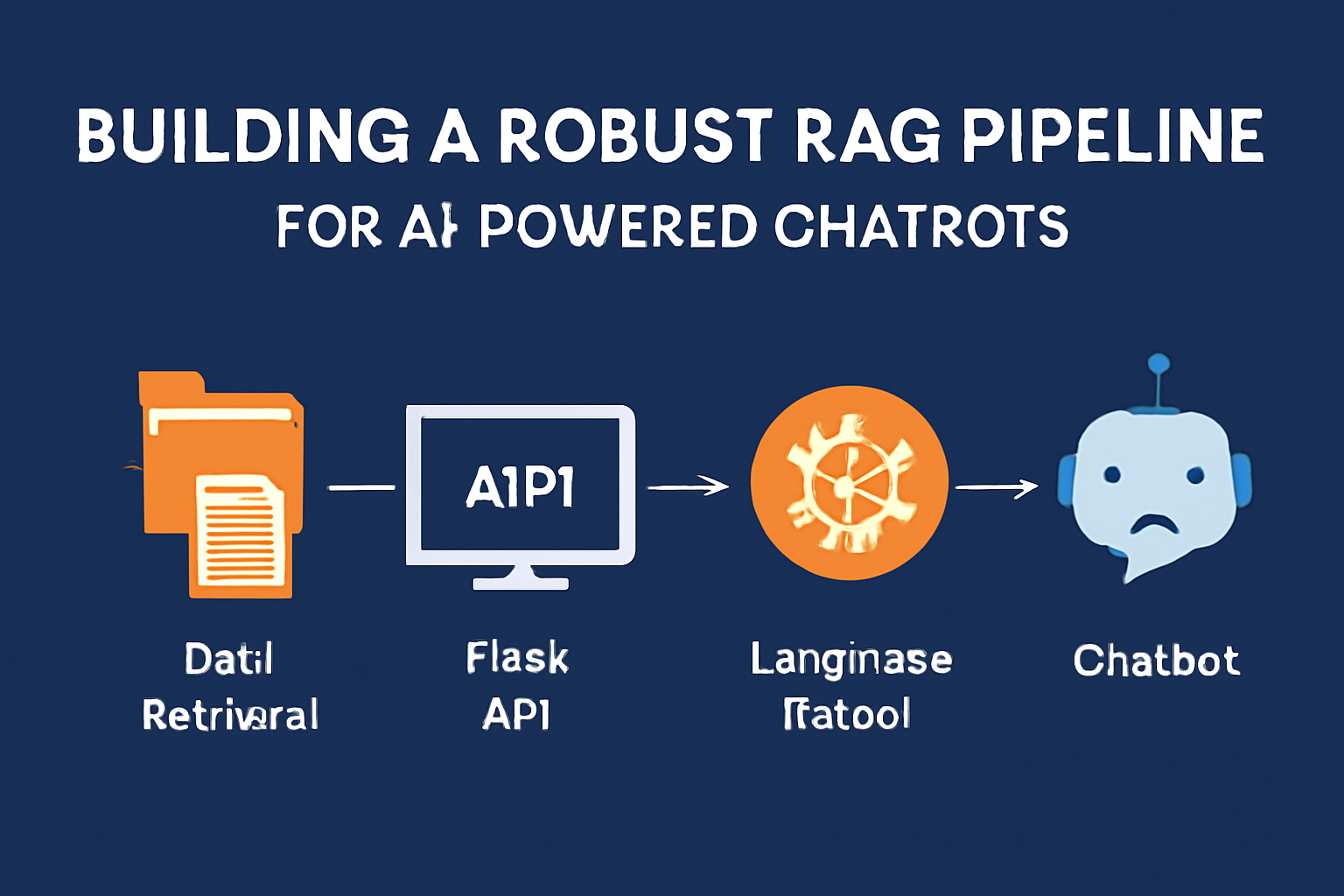
Components of a RAG Pipeline
The essential components for developing a RAG pipeline include:
-
Data Retrieval: The chatbot must extract pertinent information from a knowledge repository (e.g., PDFs, databases). We leverage FAISS (Facebook AI Similarity Search) to index and search through the embeddings of the data.
-
Embedding Models: Employ a pre-trained model that can generate embeddings for your text data. Popular choices encompass OpenAI embeddings or llama.cpp for lightweight models.
-
Flask API: A Flask-based API will manage user input, query the retrieval system, and generate responses using a language model.
-
Language Model: Once relevant data is retrieved, a language model (like Ollama or llama.cpp) is utilized to process the retrieved information and produce a coherent, human-like response.
Step-by-Step Guide to Building a RAG Pipeline
1. Establishing the Data Retrieval System
The initial step involves setting up the data retrieval system, which includes transforming your knowledge base into a set of embeddings for efficient similarity search.
- Compile your data source: Gather your documents (PDFs, JSON files, etc.) for use by the chatbot.
- Generate Embeddings: Utilize an embedding model (e.g., OpenAI or Ollama) to convert your text data into numerical vectors.
- Index the Embeddings: Following the embedding process, utilize a tool like FAISS to index the embeddings and facilitate rapid retrieval.
from faiss import IndexFlatL2
import numpy as np
# Example function to create FAISS index
def create_faiss_index(embeddings):
index = IndexFlatL2(embeddings.shape[1]) # Create index
index.add(embeddings) # Add your embeddings to the index
return index
2. Constructing the Flask API
Subsequently, establish the Flask API responsible for managing user queries and connecting them with the RAG pipeline.
- Set up Flask: Install Flask and devise a simple API structure to handle incoming requests.
- Process User Input: Upon receiving a query, the Flask app should relay the query to the retrieval system and retrieve relevant information.
- Deliver Responses: Post-retrieval, relevant documents or data are passed to the language model for response generation.
from flask import Flask, request, jsonify
from my_rag_pipeline import retrieve_data, generate_response
app = Flask(__name__)
@app.route('/api/ask', methods=['POST'])
def ask_question():
query = request.json.get('query')
# Retrieve relevant data
documents = retrieve_data(query)
# Generate response
response = generate_response(documents, query)
return jsonify({"response": response})
if __name__ == '__main__':
app.run(debug=True)
3. Generating Responses with Language Models
Post-retrieval of relevant data, the subsequent phase entails generating a response utilizing a language model. Here, you can deploy Ollama or llama.cpp to process the data and formulate a human-like answer.
from ollama import Ollama
def generate_response(documents, query):
# Concatenate documents for context
context = " ".join([doc["text"] for doc in documents])
# Direct to LLM for response generation
response = Ollama.query(prompt=f"Answer the following based on the context: {context}\nQuestion: {query}")
return response['text']
4. Testing and Evaluation
Upon constructing the system, it is imperative to test and evaluate its performance. Essential metrics to monitor include response time, relevance of answers, and system stability.
- Response Time: Gauge the time taken for the system to fetch data and generate responses.
- Relevance: Assess the quality and relevance of the responses to the user's query.
- Stability: Validate the system's capacity to manage multiple simultaneous users without crashing.
import time
def test_system():
start_time = time.time()
response = ask_question({"query": "What is the capital of Finland?"})
print(f"Response: {response}")
print(f"Time taken: {time.time() - start_time} seconds")
Conclusion
By amalgamating data retrieval with language generation, a RAG pipeline offers a more intelligent and adaptable solution for constructing AI-driven chatbots. This method not only enhances response accuracy but also renders the system more scalable by enabling real-time integration of new data. Whether you are designing a basic FAQ bot or a sophisticated assistant, leveraging a RAG pipeline can elevate your project to a higher echelon.